MCPのトークンを9割削減する退避パターン

こんにちは!つつです!
MCP サーバーを作ってしばらく運用していると、じわじわ気になってくるのがトークン消費の肥大化です。ツール定義が増えるたびにコンテキストが膨らみ、気づけば 1 回の呼び出しで想定外のトークンが飛んでいる——そんな経験、ありませんか。エアークローゼット CTO の辻亮佑さんが公開した「退避パターン」は、大きなデータを MCP の外に追い出す発想で、トークン消費を 70〜90% 削減できるというものです。ただしこれはソースコードや大きなクエリ結果を扱うツールが多い構成での最大値で、構成によって効果の幅は変わります。その構造を追いながら、MCP を自作・運用している人が知っておくべきポイントを整理しました。

MCP のトークン問題、どこで起きているのか
MCP(Model Context Protocol)は、AI モデルに「ツール」を使わせるための標準的な仕組みです。ファイルの読み書きやデータベースの検索、外部 API の呼び出しなど、さまざまな操作をツールとして定義して AI に渡せます。
**MCP(Model Context Protocol)**とは、AI モデルが外部ツールやリソースを呼び出すための標準的な通信プロトコルです。Claude などの AI が「ファイルを読む」「検索する」「API を呼ぶ」といった操作を実行できるのは、MCP が橋渡しをしているからです。
問題はここから始まります。MCP では、セッションが始まるたびに AI モデルは利用可能なツールの定義(スキーマ)を全件受け取ります。ツールの名前・引数・説明文を JSON 形式でまとめたものをコンテキストに乗せて渡すので、ツールが増えるほどセッション開始時点でのトークン消費が増えていきます。
実際に測定した事例を見ると、その規模感がよくわかります。
1 万 2,000 トークン
ツール定義が 40 個あるサーバーでは、会話を始める前からこれだけのトークンが消費されています。この事例では 1 ツールあたり 280〜320 トークン前後というのが実感値です。
本当に頭が痛くなるのは、ツールの「引数」と「返り値」もコンテキストに乗る点です。たとえば「ソースコードを MCP 経由でまるごと送る」設計にしていると、数千行のコードが一度にコンテキストへ貼り付きます。大きなクエリ結果を返すデータベース系ツールも同様で、何万行もある結果セットがコンテキストを丸ごと埋める事故が起きます。
コンテキストウィンドウには上限があります。例えば Claude では最大 200k トークンを扱えますが、ツール定義と引数・返り値で数万トークンが消えていくと、本来の会話や指示文に使える余地がどんどん削られていきます。
「退避パターン」の発想
エアークローゼット CTO の辻さんが紹介している「退避パターン」のコアアイデアはシンプルです。
大きいデータを MCP の通信路から追い出し、代わりに「参照先のキーや URL だけ」を流す。
具体的なパターンは大きく 2 つに分かれます。
リクエスト側の退避:Git へ逃がす
ソースコードや大きなファイルを AI に渡すとき、ファイルの中身を MCP に乗せてしまうのが「詰まる」パターンです。
退避パターンでは、ファイルの中身の代わりに Git リポジトリの URL を返します。AI は受け取った URL に対して git push でコードを送れるので、MCP のコンテキストにコードを貼らなくて済みます。Git は差分転送ができるうえ、ファイルサイズの上限も実質ありません。
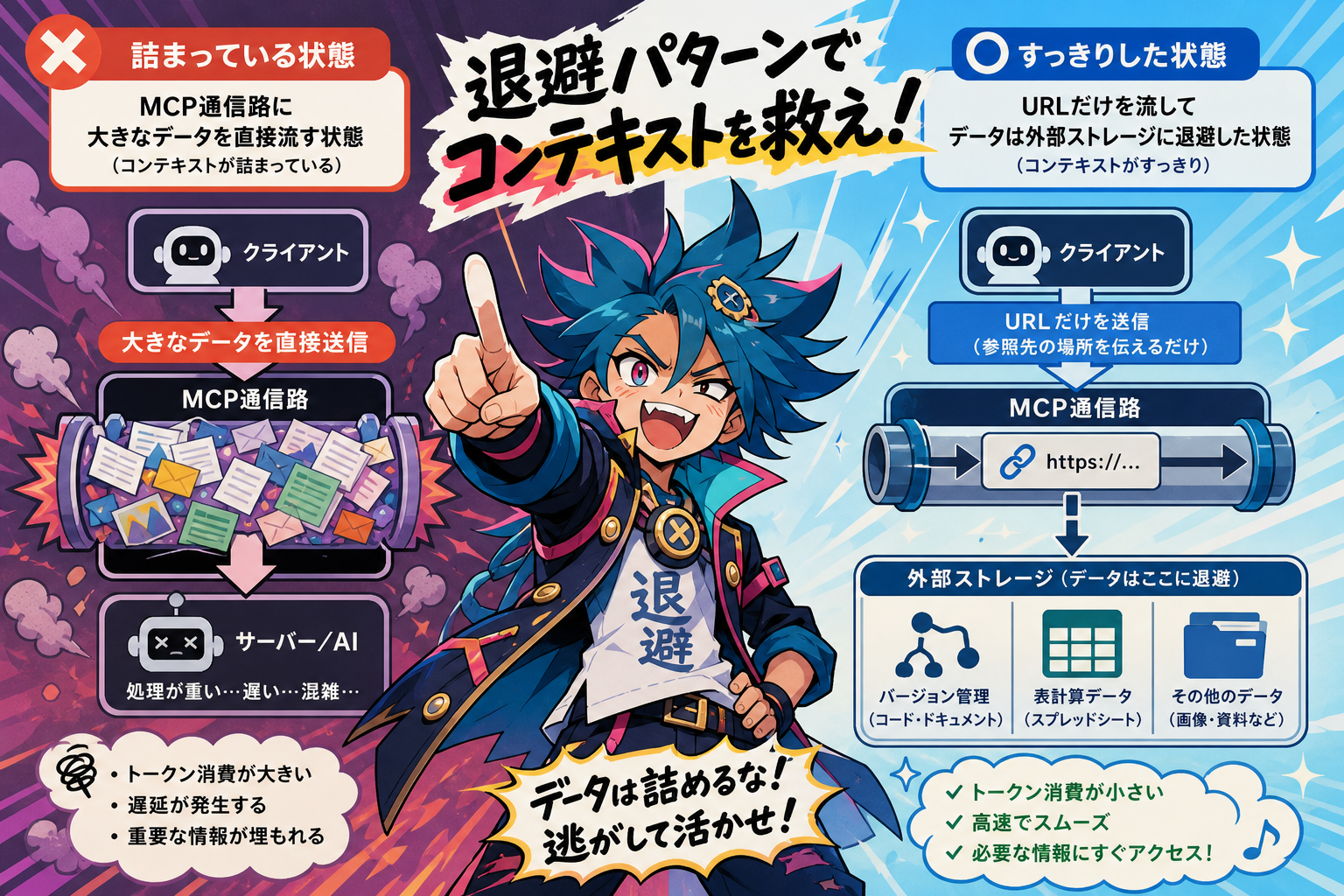
退避前の流れ
AI が「このファイルを処理して」とツールを呼ぶ
ツールがファイルの中身を MCP 経由で返す → コンテキストに何千行も貼り付く
次の呼び出しにもその履歴が残り続ける
退避後の流れ
AI が「このリポジトリに push して」と指示を受ける
ツールが Git リポジトリを初期化して URL だけを返す
AI が git push でコードを送信(MCP の外側)
コンテキストには URL しか残らない
レスポンス側の退避:Spreadsheet へ逃がす
データベースの検索結果を MCP 経由でそのまま返すのも、消費が大きくなりやすいパターンです。500 行のクエリ結果がそのままコンテキストに乗ると、それだけで数万トークンが飛びます。
退避パターンでは、一定行数を超えたら自動的に Google Spreadsheet にエクスポートし、URL だけを返すフォールバック処理を MCP サーバー側に仕込みます。コンテキストに残るのは「URL・行数・列名・エクスポートした理由」の数行だけです。
辻さんの実装では、まず LIMIT 100 でサンプル取得して分析し、全件必要なら自動でエクスポートに切り替える 2 段階方式を採用しているという設計になっているとのことです。AI が「うっかり全件取得」してもサーバー側で自動的に吸収できます。
Google Workspace との OAuth 連携を工夫すると、MCP 自体の認証と Spreadsheet や Drive への認可を同じ OAuth フローで一度に取得できます。ユーザー個人の権限でファイル保存できるので、権限管理の手間も減ります。
削減率はどのくらいか
辻さんの実運用では、全ツール合算でのトークン使用量が 70〜90% 削減されたと報告されています。MCP ツール呼び出しのログを取ることで測定しているとのことです。
ソースコードや大きなクエリ結果を扱うツールが少なければここまで下がらないケースもありますが、そういった処理が多い構成なら効果を実感しやすいと思います。
実装前に確認しておきたいこと
退避パターンを試す前に、2 点だけ押さえておくと後が楽です。
退避先が使える環境か先に確認する。Git サーバーや Google Workspace を前提にした設計なので、利用環境が対応しているか先に見ておきましょう。個人開発なら問題になりにくいですが、社内環境では制約があることもあります。
しきい値は実測してから決める。「500 行を超えたら Spreadsheet に逃がす」というしきい値は固定ではなく、自分のユースケースに合わせて調整するものです。まずはログを取りながらトークン消費を観察してから、しきい値を決めるのが安全です。
退避先(Git / Spreadsheet 等)の権限設定には注意が必要です。AI が書き込みアクセスを持ちすぎると、意図しないファイルを上書きしたり、クレデンシャルを含むファイルを push してしまったりするリスクがあります。最小権限の原則を守って設定しましょう。
僕自身も MCP サーバーをいくつか運用していて、「返り値が大きくなりがち」な箇所の肥大化は以前から気になっていました。ファイル一覧を返すだけのつもりが、ファイル内容まで返してしまっていた——というのは実際にやらかしたことがあります。この記事を読んで、返り値の設計を意識的に絞る重要性を改めて感じました。
まとめ
MCP のトークン問題は「ツールが増えるほど、呼び出しのたびに膨らんでいく」という性質があります。退避パターンの要点は 2 つです。
- リクエスト側の退避:大きなファイルを MCP に乗せず、Git URL で参照させる
- レスポンス側の退避:大きなクエリ結果を Spreadsheet にエクスポートし、URL だけ返す
どちらも「データ本体を外に追い出し、参照情報だけを渡す」というシンプルな発想です。MCP サーバーを自作しているなら、設計の初期段階からこの観点を取り入れておくと、後からトラブルを減らせるはずです。
参考リンク
- 自作 MCP サーバーのトークン消費を 9 割削減する Tips——MCP の退避パターン(辻亮佑 / エアークローゼット、Zenn)
- MCP Token Counter: Why Your Tools Are Silently Eating Your Context Window(MCP Playground)
- Code execution with MCP: building more efficient AI agents(Anthropic Engineering Blog)